三阶段优化
我们在 FAT32 设计上,采用了 rCore-Tutorial easy-fs 相同的松耦合模块化设计思路,与底层设备驱动之间通过抽象接口 BlockDevice 来连接,避免了与设备驱动的绑定。FAT32 库通过 Rust 提供的 alloc crate 来隔离了操作系统内核的内存管理,避免了直接调用内存管理的内核函数。同时在设计中避免了直接访问进程相关的数据和函数,从而隔离了操作系统内核的进程管理。
虽然我们在内核中给出了虚拟文件的抽象 File Trait,但是由于只完成的 FAT32 文件系统,内核中不存在虚拟文件系统这一抽象,也没有 Inode 层面的缓存,内核中的文件实际上将 FAT32 提供的 VirtFile 进一步封装成 KFile,每次读写都直接调用,VirtFile 提供的 read_at/write_at 方法,这导致每次写入数据都会同步到磁盘,此时 BlockCache 缓存块的作用微乎其微。
// branch: submit kernel/src/fs/fat32/file.rs
pub struct Fat32File {
readable: bool,
writable: bool,
pub inner: Mutex<Fat32FileInner>,
path: AbsolutePath,
name: String,
time_info: Mutex<TimeInfo>,
}
pub struct Fat32FileInner {
offset: usize,
pub inode: Arc<VirFile>,
flags: OpenFlags,
available: bool,
}
//branch-main: kernel/src/fs/fat32/file.rs
#[cfg(feature = "no-page-cache")]
pub fn write_all(&self, data: &Vec<u8>) -> usize {
...
loop {
let len = remain.min(512);
let offset = self.offset();
file.write_at(offset, &data.as_slice()[index..index + len]);
self.seek(offset + len);
...
}
index
}
#[cfg(feature = "no-page-cache")]
fn kernel_read_with_offset(&self, offset: usize, len: usize) -> Vec<u8> {
...
loop {
let read_size = file.read_at(offset, &mut buffer);
if read_size == 0 {
break;
}
...
}
第一阶段改进 —— Static BusyBox
在全国赛第一阶段时,我们在测试过程中发现内核跑测例的执行速度非常缓慢,比如启动 busybox 都需要花半分钟、iozone 测试中,读写速度大概为几十到几百 KB/s,显然内核的文件读写性能非常糟糕,导致没法跑完我们已经实现的测试。
此时为了尽可能跑完测试,我们发现由于大部分测试需要使用 busybox,为了避免多次解析 elf、从零创建地址空间等问题,我们采用了类似于加载 initproc 的方法。具体而言,我们将 busybox 预加载到内核中,并保存 load_elf 获取的信息。每次执行busybox时,我们直接使用保存的 load_elf 信息,并通过写时拷贝来创建所需的 busybox 进程的地址空间,更快速地创建 busybox。
// branch submit: kernel/src/task/initproc.rs
pub static ref BUSYBOX: RwLock<Busybox> = RwLock::new({
extern "C" {
fn busybox_entry();
fn busybox_tail();
}
let entry = busybox_entry as usize;
let tail = busybox_tail as usize;
let siz = tail - entry;
let busybox = unsafe { core::slice::from_raw_parts(entry as *const u8, siz) };
let path = AbsolutePath::from_str("/busybox0");
let inode = fs::open(path, OpenFlags::O_CREATE, CreateMode::empty()).expect("busybox0 create failed");
inode.write_all(&busybox.to_owned());
let bb = Arc::new(TaskControlBlock::new(inode.clone()));
inode.delete();
Busybox {
inner: bb,
}
});
pub static mut ONCE_BB_ENTRY: usize = 0;
pub static mut ONCE_BB_AUX: Vec<AuxEntry> = Vec::new();
pub struct Busybox {
inner: Arc<TaskControlBlock>,
}
impl Busybox {
pub fn elf_entry_point(&self) -> usize {
unsafe { ONCE_BB_ENTRY }
}
pub fn aux(&self) -> Vec<AuxEntry> {
unsafe { ONCE_BB_AUX.clone() }
}
pub fn memory_set(&self) -> MemorySet {
let mut write = self.inner.memory_set.write();
MemorySet::from_copy_on_write(&mut write)
}
}
虽然对于当时的我们来说算是雪中送炭。但这实际上并非合理的设计。
第一阶段优化 —— 分析 FAT32,改造簇链
在第一阶段结束后,我们通过追踪读写相关代码所耗费的时间, 比如:
// branch-main: crates/fat32/src/vf.rs
pub fn write_at(&self, offset: usize, buf: &[u8]) -> usize {
#[cfg(feature = "time-tracer")]
time_trace!("write_at");
...
}
pub fn read_at(&self, offset: usize, buf: &mut [u8]) -> usize {
#[cfg(feature = "time-tracer")]
time_trace!("read_at");
}
#[cfg(feature = "time-tracer")]
start_trace!("cluster");
let pre_cluster_cnt = offset / cluster_size;
#[cfg(feature = "time-tracer")]
start_trace!("clone");
let clus_chain = self.cluster_chain.read();
#[cfg(feature = "time-tracer")]
end_trace!();
let mut cluster_iter = clus_chain.cluster_vec.iter().skip(pre_cluster_cnt);
#[cfg(feature = "time-tracer")]
end_trace!();
(TimeTracer 用于记录执行到当前代码的时的系统时间, 当 TimeTracer drop 时统计期间消耗的时间)
首先定位到影响 FAT32 文件直接读写文件过程中最为耗时的操作:遍历文件的簇链过程中,不断在 FAT 表中查询下一簇的位置。我们实现的 FAT32 文件系统所有读写,包括遍历簇链的操作都是依赖 BlockCache 提供的 get_block_cache 方法,但其中遍历簇链这个操作非常的频繁,导致整个读写过程耗时严重。
读写文件时:
// branch-submit: crates/fat32/src/vfs.rs: read_at/write_at
while index < end {
let cluster_offset_in_disk = self.fs.read().bpb.offset(curr_cluster);
let start_block_id = cluster_offset_in_disk / BLOCK_SIZE;
for block_id in start_block_id..start_block_id + spc {
...
}
if index >= end {
break;
}
curr_cluster = self.fs.read()
.fat.read()
.get_next_cluster(curr_cluster).unwrap();
curr_cluster = clus_chain.current_cluster;
}
// branch-submit: crates/fat32/src/fs.rs
pub fn get_next_cluster(&self, cluster: u32) -> Option<u32> {
let (block_id, offset_in_block) = self.cluster_id_pos(cluster);
let next_cluster: u32 = get_block_cache(block_id, Arc::clone(&self.device))
.read()
.read(offset_in_block, |&next_cluster: &u32| next_cluster);
assert!(next_cluster >= 2);
if next_cluster >= END_OF_CLUSTER {
None
} else {
Some(next_cluster)
}
}
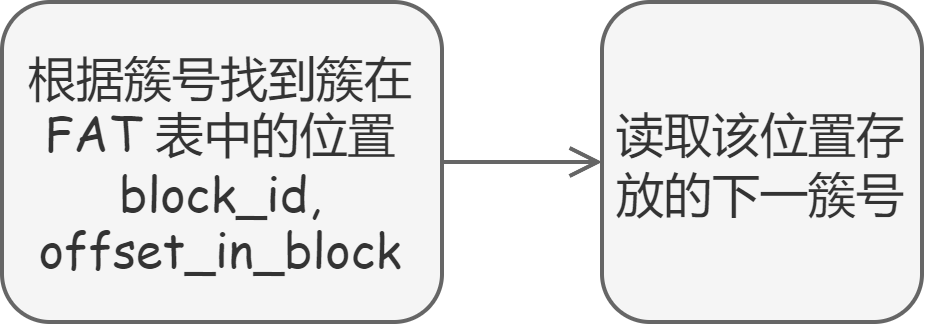
由于该操作对于同一文件的读写非常频繁,并且大部分情况下,特别是多次读文件时,所获取的簇链信息不变,但每次都要重新从 BlockCache 中读取,显然这个过程是可以优化的。一个非常容易想到的方法就是:
- 在打开文件时,预读簇链,将簇链信息保存下来
- 对于可能会修改簇链的文件写操作,如在文件 increase_size 时,重新读取簇链
于是我们对 FAT32 文件系统的簇链设计做出修改:
// branch-main: crates/fat32/src/fat.rs
pub struct ClusterChain {
...
pub(crate) cluster_vec: Vec<u32>,
}
// branch-main: crates/fat32/src/vf.rs
// open / increase_size 时
loop {
...
let next_cluster = get_block_cache(block_id, Arc::clone(&self.device))
.read()
.read(offset_left, |&cluster: &u32| cluster);
if next_cluster >= END_OF_CLUSTER {
break;
} else {
self.cluster_vec.push(next_cluster);
};
}
对比视频:IMAGE
第三阶段解决 —— 更进一步,Page Cache
其实经过以上优化,内核运行测试时的速度已经能够接受了。但是问题的关键还是在于上面提到的:由于只完成的 FAT32 文件系统,内核中不存在虚拟文件系统这一抽象,也没有 Inode 层面的缓存,内核中的文件实际上将 FAT32 提供的 VirtFile 进一步封装成 KFile,这导致每次写入数据都会同步到磁盘。
文件读写时,大量的磁盘直接 IO,才是急需解决的问题。
我们首先想到了可以通过实现 TempFS (将文件存储在系统的内存中而不是磁盘上),将测试过程中内核关于文件的操作如创建,读写等,都交给 TempFS,不必每次都写回 FAT32。或者是在目前的 KFile 基础上加上 PageCache 减少对磁盘的频繁访问。
由于缺乏相关实现经验,查看了部分第一阶段提交时的优秀队伍的是否有做相关工作,希望从中学到实现思路。
最后我们选择参考同一期的优秀队伍 TitanixOS 的 PageCache 实现思路,为内核加入 PageCache 机制。
相关结构如下:
pub struct KFile {
// read only feilds
readable: bool,
writable: bool,
path: AbsolutePath,
name: String,
// shared by some files (uaually happens when fork)
pub time_info: Mutex<InodeTime>,
pub offset: Mutex<usize>,
pub flags: Mutex<OpenFlags>,
pub available: Mutex<bool>,
// shared by the same file (with page cache)
pub inode: Arc<Inode>,
}
pub struct Inode {
pub file: Mutex<Arc<VirtFile>>,
fid: u64,
#[cfg(not(feature = "no-page-cache"))]
pub page_cache: Mutex<Option<Arc<PageCache>>>,
#[cfg(not(feature = "no-page-cache"))]
pub file_size: Mutex<usize>,
}
关于 Inode 的设计:
- 配合 InodeCache 加快查找效率,实现文件的缓存
- file 字段为 FAT32 提供的 VirtFile
- 关于在 Inode 中保存文件的大小的理由:
- 测试过程中创建的文件的读写操作实际上是在内存中通过 Page Cache 进行的,往往不会直接写回文件系统(特别是在单核下,大量的对磁盘的直接读写会导致内核执行速度变慢)。
- 为了提高测试速度,我们使用 Rust Feature 机制,默认关闭 Inode Drop 时的写回操作(实际我们在多核下测试,开启写回操作对速度影响不大),相当于借助 FAT32 VirtFile 的 ”外壳“ 实现了一个不算标准的 TempFS;
- 文件读写过程中需要用到 file_size 参数,加上不会每次写文件或关闭文件后直接写回文件系统,故不能通过在文件系统中读取文件大小的方式来获取文件大小(不一致);
- 不同进程对该文件进行写操作时会改写文件的大小,使用 Inode Cache 再次打开文件时必须保证文件大小的一致性。
// branch-main: kernel/src/fs/fat32/file.rs
pub struct InodeCache(pub RwLock<BTreeMap<AbsolutePath, Arc<Inode>>>);
pub static INODE_CACHE: InodeCache = InodeCache(RwLock::new(BTreeMap::new()));
// branch-main: kernel/src/fs/page.rs, page_cache.rs
pub struct PageCache {
inode: Option<Weak<VirtFile>>,
// page number -> page
pub pages: RwLock<BTreeMap<usize, Arc<FilePage>>>,
}
pub struct FilePage {
pub permission: MapPermission,
pub data_frame: FrameTracker,
pub file_info: Option<Mutex<FilePageInfo>>,
}
pub struct FilePageInfo {
/// 页的起始位置在文件中的偏移(一定是页对齐的)
pub file_offset: usize,
pub data_states: [DataState; PAGE_SIZE / BLOCK_SIZE],
inode: Weak<VirtFile>,
}
// branch-main: kernel/src/fs/page.rs
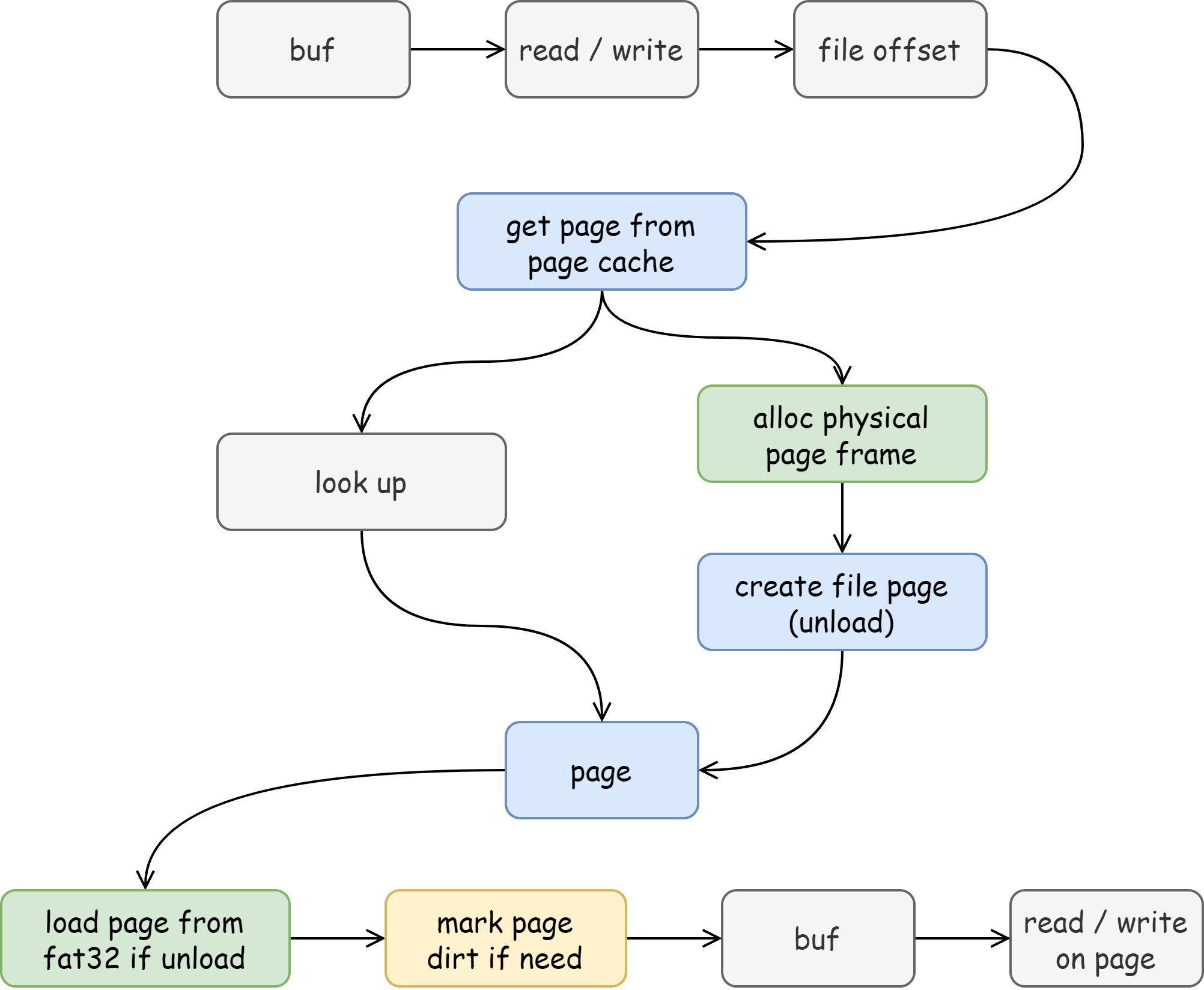
for idx in start_buffer_idx..end_buffer_idx {
if file_info.data_states[idx] == DataState::Unload {
let page_offset = idx * BLOCK_SIZE;
let file_offset = page_offset + file_info.file_offset;
let dst = &mut self.data_frame.ppn.as_bytes_array()
[page_offset..page_offset + BLOCK_SIZE];
let mut src = vec![0u8; BLOCK_SIZE];
file_info
.inode
.upgrade()
.unwrap()
.read_at(file_offset, &mut src);
dst.copy_from_slice(src.as_slice());
file_info.data_states[idx] = DataState::Load;
}
}
文件操作图片: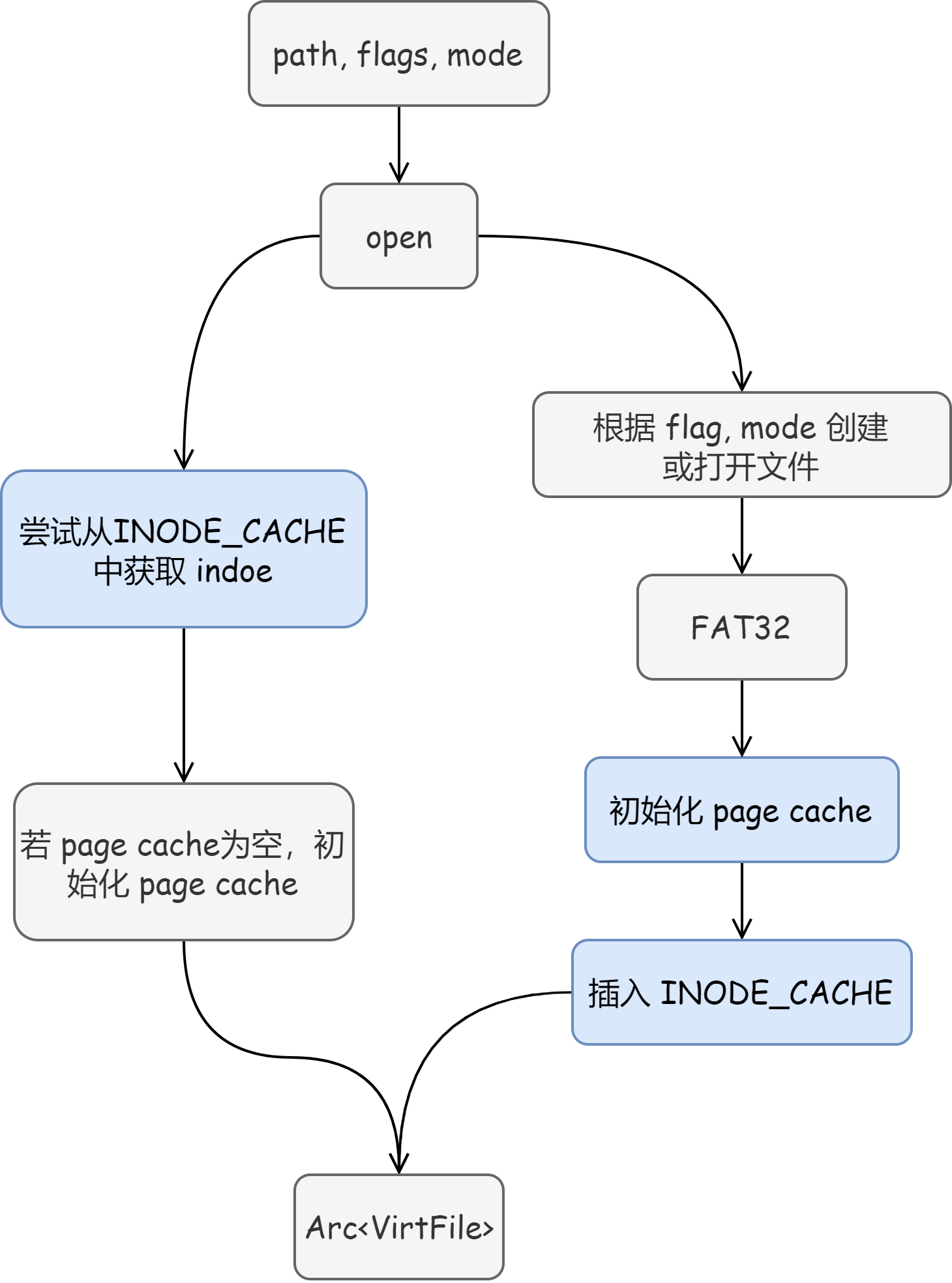
三阶段对比(单核下)
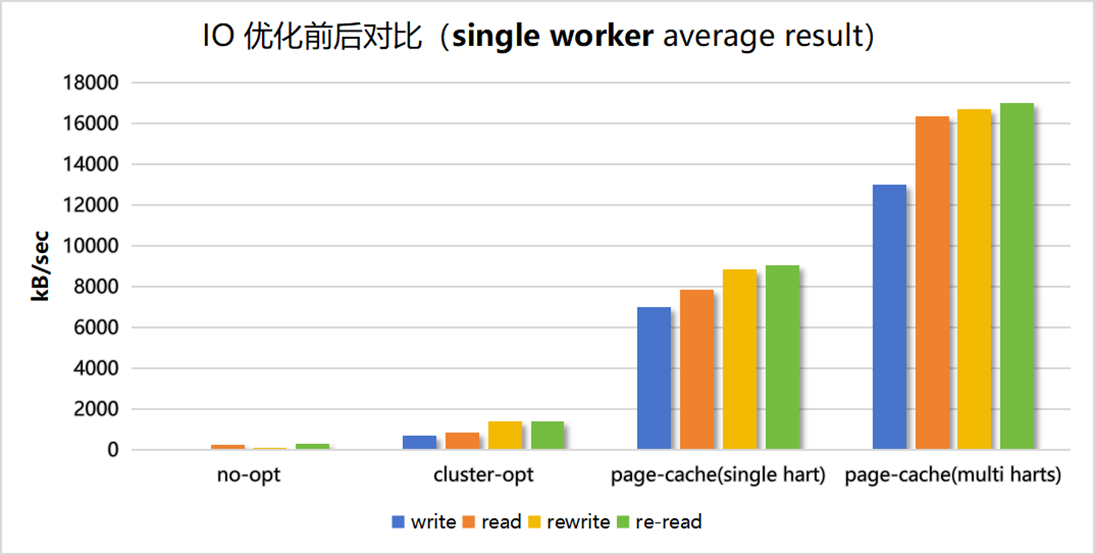
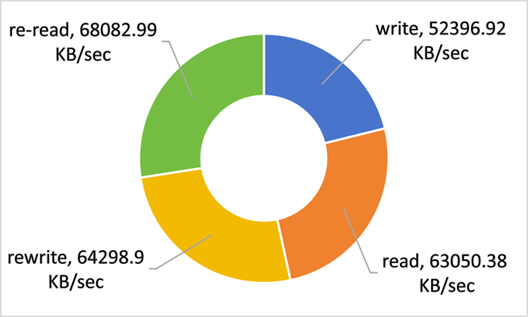
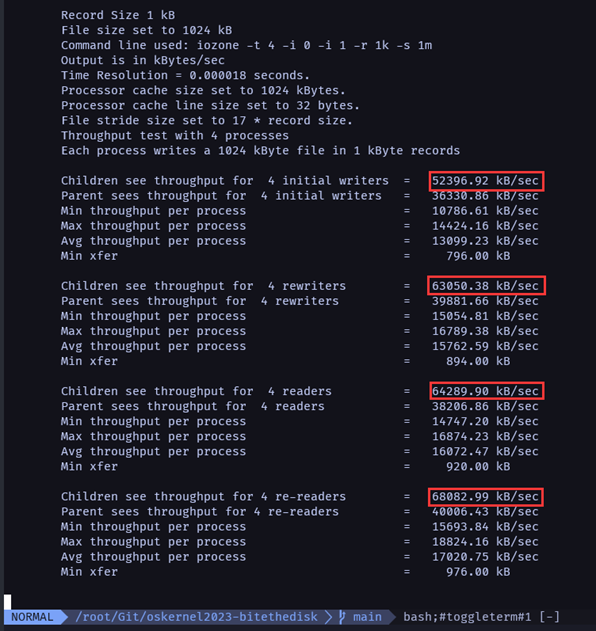
此,我们的内核文件优化过程暂时告一段落。